Posted by Nodus Labs | April 14, 2022
Measuring Propagation Dynamics of Ideas using Network Analysis
Any discourse can be represented as a network. A narrative, then, is a path through this network. Depending on how the journey is made, the meaning changes. Measuring the dynamics of this movement through ideas can help us understand how they propagate, and how this dynamic structure of meaning unfolds in time.
On a very practical level, if we are talking about a certain topic, like network science, we can do it in ways where we jump across the main theoretical tenets, or we can dive into the specifics and then switch to another subject. This defines how our ideas will propagate through the text.
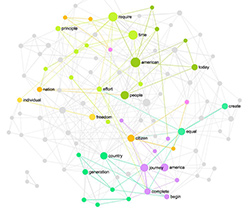
Consider, for instance, this article from Wikipedia on Text Mining, visualized using InfraNodus text analysis tool:
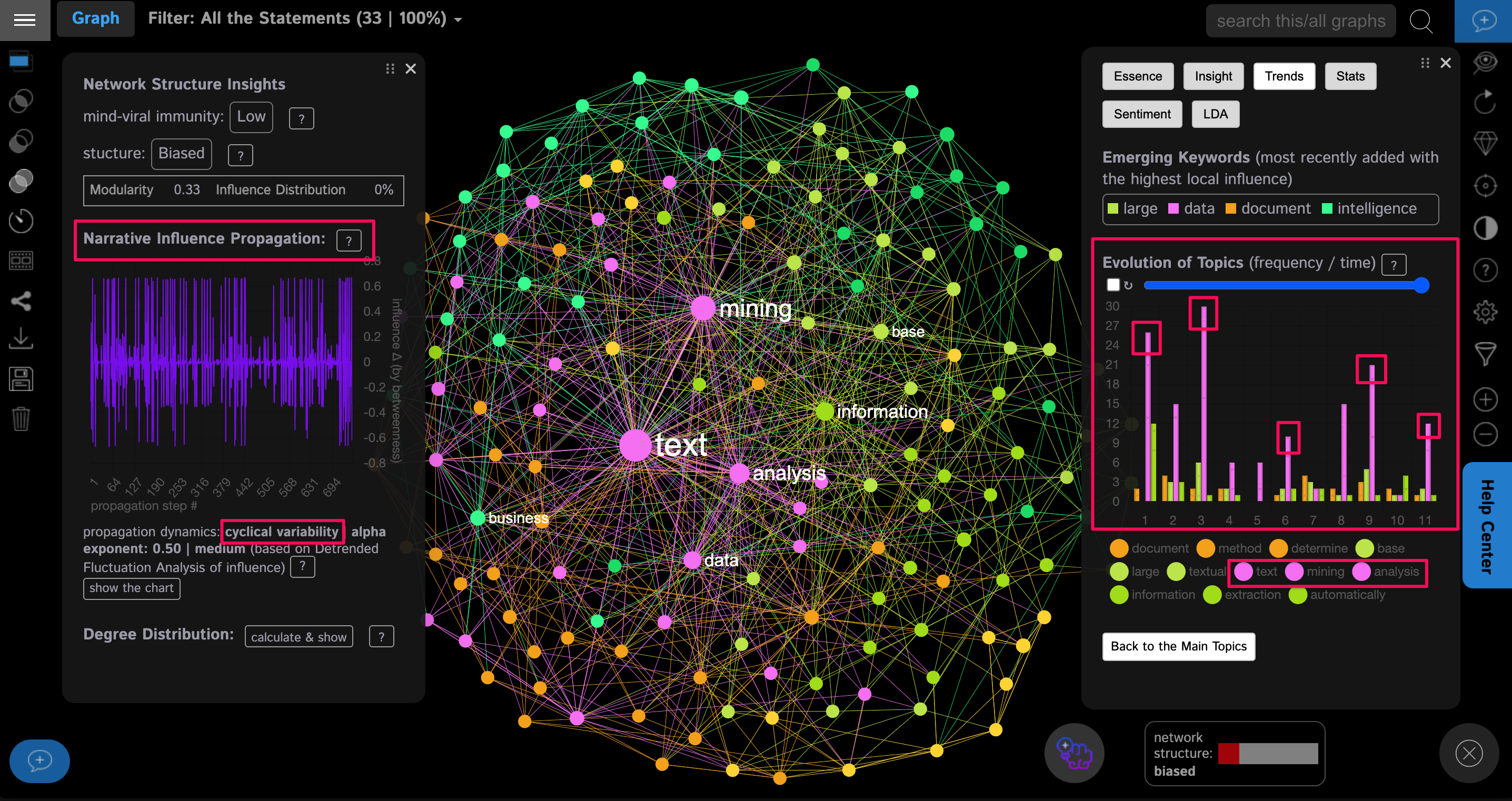
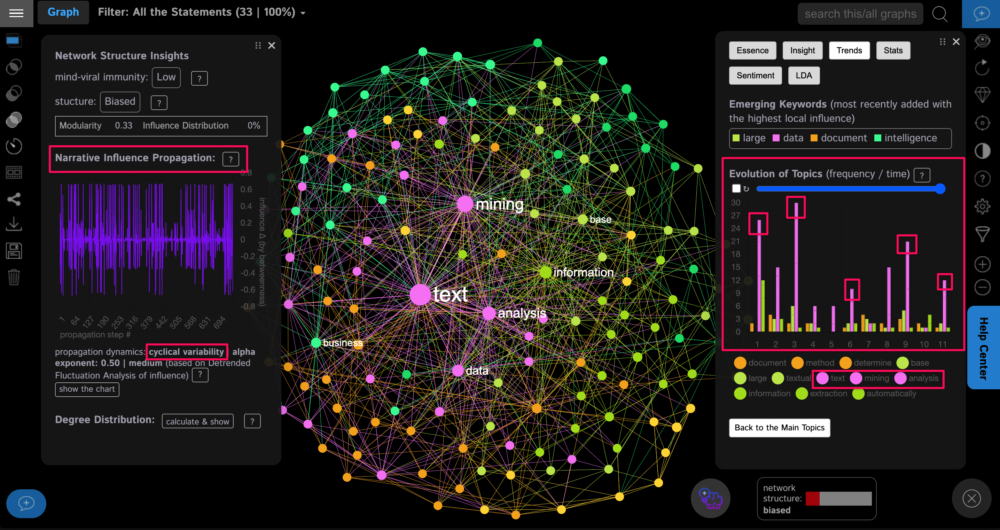
As we can see, the words “text”, “mining”, “analysis” are recurrent throughout the narrative. The Trends panel on the right shows that they constantly re-appear in the text, which is not surprising, because this is the format of Wikipedia.
The narrative dynamics panel on the left shows a graph that indicates the word sequence on the X-axis, and the global influence of that word on the Y-axis (based on its betweenness centrality score). Using this graph, we can see how most of the time the most influential words tend to re-appear in the text, except for 1 place, about 60% into the narrative, where the smaller words are more frequently mentioned (indicating that the narrative went into a specific topic, away from the most influential words).
For the sake of comparison, let’s look at the article on Text Analysis from MonkeyLearn, an online service for AI-based text analysis tools:

As we can see, it is less “rhythmical” than the Wikipedia text. The most influential terms, such as “text” and “analysis” are frequently mentioned at the beginning of the article, but then they recede. The new, more specific topics, such as “machine learning” and “customer service” begin to come up (check the “Trends” panel on the left). This is also confirmed by the network structure panel, which shows that the rhythm of propagation is not cyclical (as it was in the case of Wikipedia), but, rather, irregular.
Practically, this means that the second text from the MonkeyLearn website has a less regular and representation of the most influential concepts. It tends to go further into detail than the Wikipedia text, it also goes deeper in-depth on specialized topics.
Narrative Dynamics for Text Classification
As we can see above, a single article on a specific topic (text analysis) can be written in multiple ways. The Wikipedia article was more rhythmical: the most influential concepts are mentioned regularly throughout the text. The more specialized MonkeyLearn article on the topic was less regular: while it started from the main concepts like “text” and “analysis”, it later went into more specific related topics, such as “machine learning” and “customer service” — talking about the technical implementation and a possible use case.
We may be able to use this insight about a text’s structure to better understand its intention and for classification.
Texts that are made to inform or convince will usually focus on a few main concepts, all other concepts are to serve the dominant meaning. Propagation of this narrative in time will have a steady rhythm, repeating as chorus the main concepts over and over again. Many great speeches were made this way too. “I have a dream” is one of them.
On the opposite side, if a text’s narrative unfolds irregularly, that is, sometimes we discuss very important concepts, then we zoom into the specifics, stay there — nearly esoteric and introverted for some period of time — and then jump to the crossroads of meaning, leaping our way across our own semantic universe onto another topic. That is a different kind of narrative that seeks to educate or to produce emotions, not to convince or inform.
All these different ways of narrative propagation can be very useful to help us see texts in a different way and read / write not only using the words, but also other representations.
Social Networks Analogies
Interestingly, there are multiple analogies that can be made between text networks and social networks. We already know that the structure of social networks influences their capability to propagate information. If a network is densely connected and does not have distinct clusters it is more likely to pass the information through, but that propagation will have a shorter life cycle (good for fads or trends). If a network consists of several distinct communities of nodes, it may be more difficult to propagate the message through the whole network, but once it’s inside, it is much more likely that information will stay within for a longer time.
We can see a text network as a social network. The concepts are the nodes that are used to propagate meaning. If a network is dispersed, it’ll be more difficult to propagate certain ideas, but they will be more diverse. If it’s interconnected into a homogeneous cluster, propagation is easier, but there’s no place for plurality.
The additional dimension that we propose shows us how we can measure the nature of this propagation in time. A structure is a snapshot, however, it’s interesting to see how it evolves. Using the measure of influence probation in time, we can see how frequently the message passes through the “crossroads of meaning circulation”, touching upon the most influential topics. Therefore, if we have two networks with the same structure, we can see how those structures actually unfold in time.
Technical Aspect: Detrended Fluctuation Analysis (DFA)
When analyzing the narrative structure we use Detrended Fluctuation Analysis. This measure is used in InfraNodus to label the variations in influence propagation and to ascribe one of the 4 states to the narrative dynamics: cyclical, irregular, fractal, and complex. We can then use this insight to modify the existing text or to better choose the strategy that needs to be employed to propagate certain ideas through a discourse based on our initial intentions.
We have used Detrended Fluctuation Analysis or DFA multiple times when estimating variability of physical movement in our other project, EightOS body-mind operating system. DFA is based on measuring the nature of variability in a process. The basic algorithm is the following:
- remove the trend from the time-series data
- chop the time-series into windows of various sizes (across different scales)
- check variations in each of those scale-windows
- see how these variations differ depending on the scale
- tag the dynamic state with alpha coefficient that shows the nature of the variation
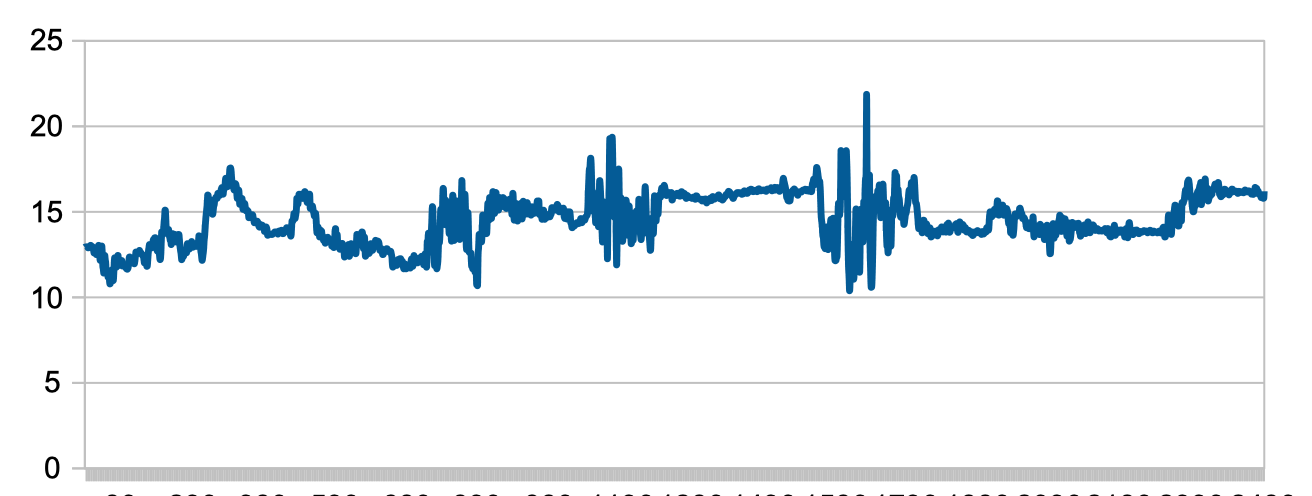
In the context of text analysis, we use DFA data to measure variability of influence (which is measured using network betweenness centrality for the nodes). If this variability doesn’t change across the different scales (meaning the time we observe a process), then the process is marked as random. An increase in the time of the observation does not change the dynamic nature of the observed process. If, on the other hand, the longer we look at the process, the higher is the variability, then we know that propagation is less regular. Therefore, our narrative is less rhythmical. Longer chunks of texts will have a variety of nodes, not only the most influential terms. This indicates a less homogeneous structure in time, therefore, a more complex propagation process.
The Experiment is Open…
If you are interested to try this approach on your own text data, log on www.infranodus.com and upload your own texts. Let us know about your results!