Posted by Nodus Labs | July 29, 2018
Tutorial: Text Mining Using LDA and Network Analysis

Topic modeling is used to discover the topics that occur in a document’s body or a text corpus. Latent dirichlet allocation (LDA) is an approach used in topic modeling based on probabilistic vectors of words, which indicate their relevance to the text corpus.
In this tutorial we present a method for topic modeling using text network analysis (TNA) and visualization using InfraNodus tool. The approach we propose is based on identifying topical clusters in text based on co-occurrence of words. We will demonstrate how this approach can be used for topic modeling, how it compares to Latent Dirichlet Allocation (LDA), and how they can be used together to provide more relevant results.
You will see how LDA may be less efficient for some texts as it tends to only focus on the terms’ frequency and disregard the structure of a text (“bag of words” or “vector space” model, also n-gram model where n=1). Text network analysis, on the other side, takes into account both the text’s structure and the words’ sequence, providing more precise results in some cases.
We will start from a general overview of the two approaches and will then run a test on real data to show the differences between the two approaches and how they could be used together.
Latent Dirichlet Allocation (LDA) — How It Works
To make the long story short and to avoid complicated maths we will go through how LDA works glossing over some details, just to give a general picture.
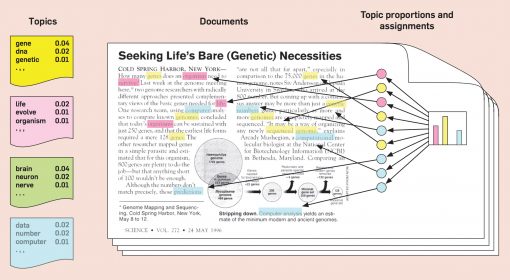
LDA, at its core, is an iterative algorithm that identifies a set of topics related to a set of documents (Blei 2003). In order for it to work, LDA needs to know how many topics it’s searching for beforehand. For example, if we have one document we can specify that we’re looking for four different topics. LDA will then go through each word that appears in the text, randomly ascribe it to one of the four topics, and calculate a special score for this word based on the probability that this word will be found in this particular topic in the set of documents (in our case, only one document). LDA then ascribes this same word to another topic and calculates the same score. After many iterations we get a list of words in each topics with probabilities. For each topic we can select the top 5 words with the highest probability of belonging to that particular topic and we will get a pretty good description of what the topic is about through the combination of words with the highest probability. Naturally these words tend to co-occur together in the same context. Words with high frequency will take more prominent position in each topic (Blei 2012). A distinguishing characteristic of latent Dirichlet allocation is that all the documents in a collection share the same set of topics, but each document exhibits those topics with different proportion.
LDA is perhaps the most popular and well-tested method for topic modeling today. Since it was introduced a few years ago, it’s gone through some upgrades. For example, lda2vec is a model that combines LDA with word2vec, providing better insights about the words and topics. LDA itself is a special case of pLSA — Probabilistic Latent Semantic Analysis, which is a modification of LSA (Latent Semantic Analysis).
One of the main drawbacks of LDA is that it’s quite complex to understand and that it requires a precise number of topics in order to proceed. Moreover, the fact that it’s a bag-of-words model (i.e. the sequence of words and the structure of narrative is lost) may lead to some losses, especially for texts with complex narrative structure (e.g. several topics that re-occur in different parts of the text). We also tend to lose the relations between the topics. Moreover, if certain words re-occur throughout all text they might be present in all the topics identified making the results less precise.
This is why there’s been numerous efforts to find other, more efficient approaches, and text network analysis is one of them.
Text Network Analysis and Visual Topic Modeling
In text network analysis a text is represented as a graph using InfraNodus text analysis tool. The words are the nodes and co-occurrences of the words are the connections between them (see Paranyushkin 2011 and Paranyushkin 2019). In order to make the graph more precise and representative of the way we read, we can implement the Landscape reading model (Broek et al 1999) scanning the connections between the words in 4-word windows. Such approach yields a graph that traces the activation of each concept in relation to others, so that it’s possible to see how the different words are connected in a specific narrative.
Once the graph is constructed, we can use community detection algorithms to identify the groups of nodes that are more densely connected to one another than to the rest of the network as well as the most influential nodes (words) inside the graph using the measure of betweenness centrality or degree. This data can be obtained both in qualitative and quantitive way, making text network analysis appropriate both for machine learning tasks and human interpretation.
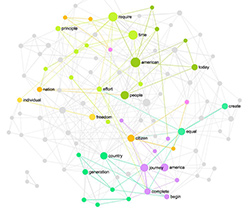
As an example, here’s a graph of the same text fragment as was shown in the LDA example above made using text network analysis tool InfraNodus:
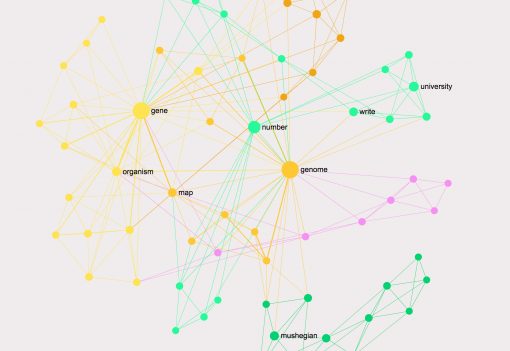
The words that tend to co-occur next to each other in this text are organized in communities (indicated with distinct colors), while the most influential words (the nodes with the highest betweenness centrality) are shown bigger on the graph.
It can be seen easily that the main topics in this short text are:
gene – organism
genome – map and
numbers
which sums up this short text pretty well (it is about the number of genes an organism needs to survive).
A very important feature of text network analysis is that it doesn’t only detect the main topical clusters but also shows the relation between them — something that is missing from LDA analysis.
Text Network Analysis vs LDA
We will now compare how the two approaches perform on medium-sized documents with a ground truth value: that is, the Wikipedia articles that have been manually categorized and ranged according to the topics that editors deemed appropriate for the texts. Later we will be publishing a more extensive research on comparing the two approaches using a large and widely accepted corpus of documents.
In order to evaluate the quality of text network analysis and LDA we will be using InfraNodus open-source Javascript / Node.Js based tool for text network analysis and LDA.js open-source Javascript package. We set both algorithms to identify 4 topics in a document and will compare their results to the topics that have been set manually for each article by Wikipedia editors.
Case 1: Wikipedia Article on Text Mining
.
Main topics identified by LDA:
1: text – mining – applications – copyright – biomedical
2: information – textual – intelligence – business
3: content – analysis – data
4: text – mining – information – analysis

Main topics identified using text network analysis:
1: text – mining – analytics – application
2: analysis – data – textual – network
3: document – content – base
4: business – intelligence – research

Main topics according to Wikipedia editors:
1: Text mining
2: Artificial intelligence applications
3: Applied data mining
4: Computational linguistics
5: Natural language processing
6: Statistical natural language processing
7: Text
We can see that both methods performed quite well on this article, however, the topics identified by text network analysis contain a cluster on “business intelligence research” making it clearer what text mining is actually used for. LDA gave slightly more importance to the terms “copyright” and “biomedical”, which are also contained in the first topic identified by TNA (applications of text mining), but not at the first positions. You can check this using the embedded TNA graph below:
Case 2: Wikipedia Article on Deconstruction (philosophical concept)
.
Main topics identified by LDA:
1: influence – nietzsche – political – metaphysics
2: deconstruction – derrida – derrida’s – critique
3: derrida – derrida’s – searle – speech
4: language – meaning – text – analysis

Main topics identified using text network analysis:
1: derrida – deconstruction – term – text
2: meaning – language – word – sign
3: searle – austin – speech – theory
4: opposition – philosophical – position – history

Main topic categories according to Wikipedia editors:
Deconstruction
Literary criticism
Philosophical movements
Philosophy of language
Postmodern theory
In this case in LDA results we have the word “derrida” and “derrida’s” appearing in several topics, making it harder to distinguish topics clearly from one another. In the TNA method we propose a word can only belong to one topic, so the topical structure it produces is clearer. Some of the topics that LDA and TNA produced are similar, such as “searle / austin / speech”, related to the Philosophy of Language topic in Wikipedia.
Conclusions
We have demonstrated the difference between LDA and text network analysis (TNA) methods for topic modeling. We have shown that while LDA is a more popular method it does not always produce very precise results and it lacks information about the relation of topics to one another. These deficiencies are resolved by the text network analysis method we proposed, which maintains the structure of the narrative and shows the relations between different topics, both on quantitive and qualitative levels.
We will perform a more thorough analysis of the both methods and compare their performance using a larger text corpus. For now we invite you to try text network analysis on your documents using InfraNodus tool and, please, feel free to contact us if you have any comments, suggestions or feedback about this approach.