Posted by Nodus Labs | June 21, 2013
Group Profiling Using Text Network Analysis
Any group of people working together has a field of interests, which can be represented as a network of interrelated concepts. Mark might be interested in studying trends and fashion, while Joanne might be into fashion and arts. Identifying those interests and their relation to one another can be very useful for improving the collaboration, indicating the vantage points as well as the structural gaps within the group.
Text network analysis can be used for such quick group profiling. The members of the group can write a short text (or be interviewed) outlining their interests. Alternatively, publicly available texts can be used to gather the data. Next, graph visualization of this aggregated text can help identify the most prominent topics and their relations within that text corpus.
In preparation to our seminar at Complex Networks lab in Paris, we put together this case study to demonstrate how we used text network analysis to quickly identify the main interests of the researchers working at the lab.
Project: Group profiling using text network analysis
Client: Complex Networks group at LIP6 lab (Pierre and Marie Curie University Paris VI)
Objective: Identify the main research directions at the lab and the general scope of the lab’s interests
We used the abstracts of the 37 papers published by the lab’s researchers during 2010-2013 available on Complex Networks lab’s website. The resulting text corpus was submitted to our Textexture software, which visualized those abstracts as a network. More information about the methodology used is available in this paper, we will provide only a brief overview here.
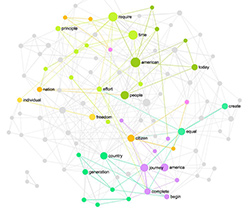
First, the stop words (such as “a”, “the”, “is”) are removed from the text. Second, the remaining words are brought to their morphemes (i.e. “studied” = “study”). Third, the resulting text is scanned twice: the words are represented as nodes and their co-occurrences are represented by the edges. The graph information is then submitted to Gephi Toolkit in order to calculate the basic measures, including betweenness centrality as well as the community structure (modularity) for the graph. As the final step, the graph is visualized in Textexture using Sigma.Js library. It can then be used as a visual reference that provides an overview of the main concepts inside the text (bigger nodes in the graph indicating higher betweenness centrality measure), as well as the different clusters of interrelated concepts (indicated with distinct colors).
It should be noted that the choice of betweenness centrality measure to indicate the most influential concepts inside the text corpus is due to that measure’s ability to emphasize the nodes that join different distinct communities together. That is, the words which occur not only frequently inside the text corpus, but also the ones joining the different contexts (topics) that are present inside the text.
The community structure indicates the clusters of words that occur more often next to each other than with the rest of the words inside the text. The distinct communities (marked with a distinct colors inside the graph) indicate the contexts or topics present inside the text.
The graph can also be used to get the excerpt of the relevant part of the text by clicking on the nodes in the graph (only inside Textexture interface).
A brief overview of the resulting graph yields the following insights:
The most influential terms inside the text are:
network • community • graph • dynamics
2)
The main communities (contexts or topics inside the text) are:
a) network • node • data • complex
b) community • time • propose • method
c) graph • model • show • result
d) dynamic • study • information • diffusion
e) internet • topology
Subsequent analysis of the relevant excerpts (which can be performed by clicking on the according nodes inside the graph), as well as a more detail qualitative analysis of the graph indicates that the most prominent topics in the Lab’s research are:
1) Studies of complex networks and graph modelling
2) Community-detection (with a strong emphasis on time in analysis of the network data)
3) Study of dynamic networks and information diffusion
4) Studies of internet topology As a result, we have a quick visual overview of the Lab research group’s interests using the data aggregated from the abstracts of their recent research.
The study could be further improved by adding the social network information (relating the abstracts of papers to their authors), creating a bi-partite graph and making the analysis more precise (perhaps, even identifying the most influential researchers within the lab).
Another interesting thread of research is to study the relations between the interests of different groups and identify similarities as well as differences in the common fields of interests.