Posted by Nodus Labs | July 29, 2018
Tutorial: Text Mining Using LDA and Network Analysis

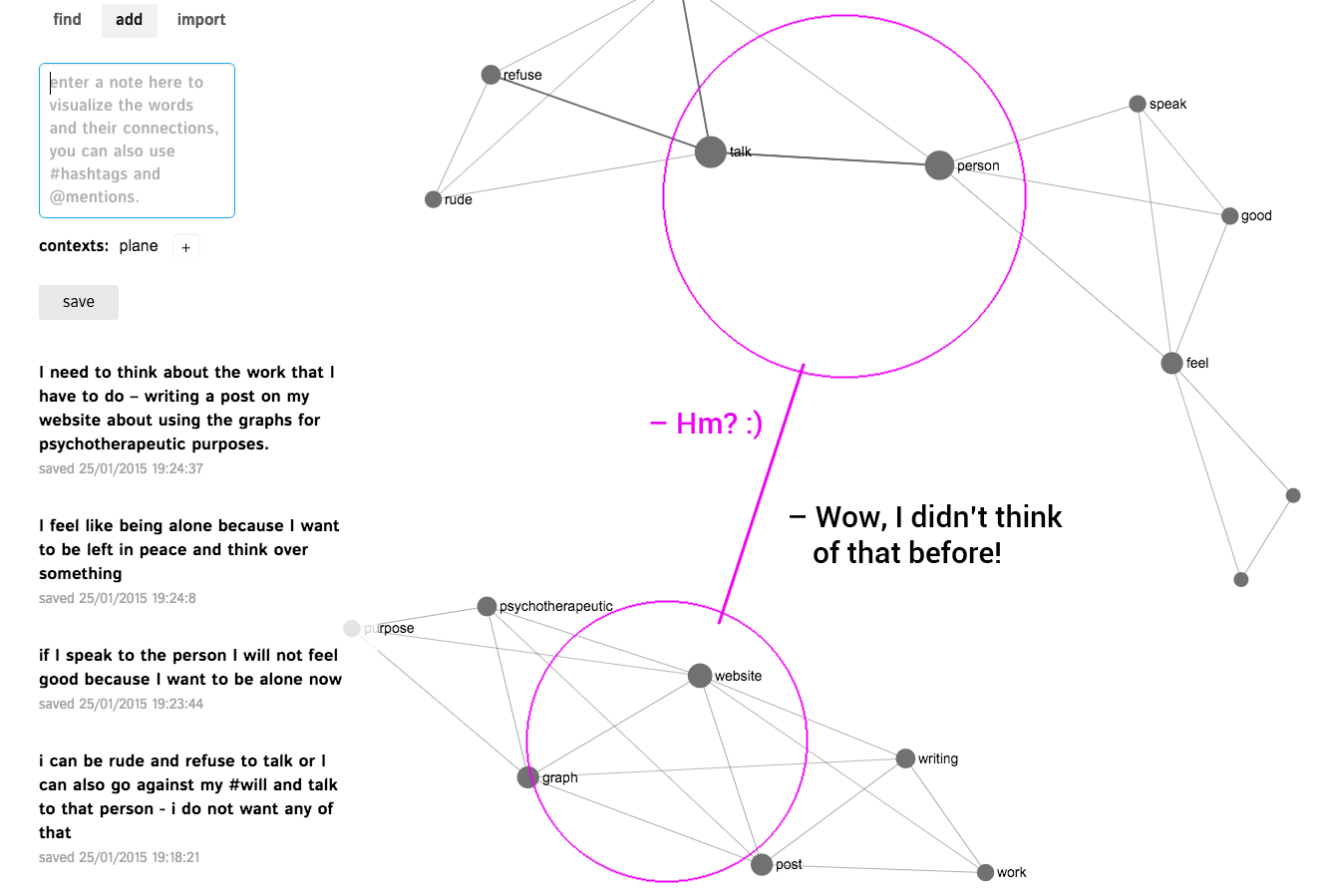
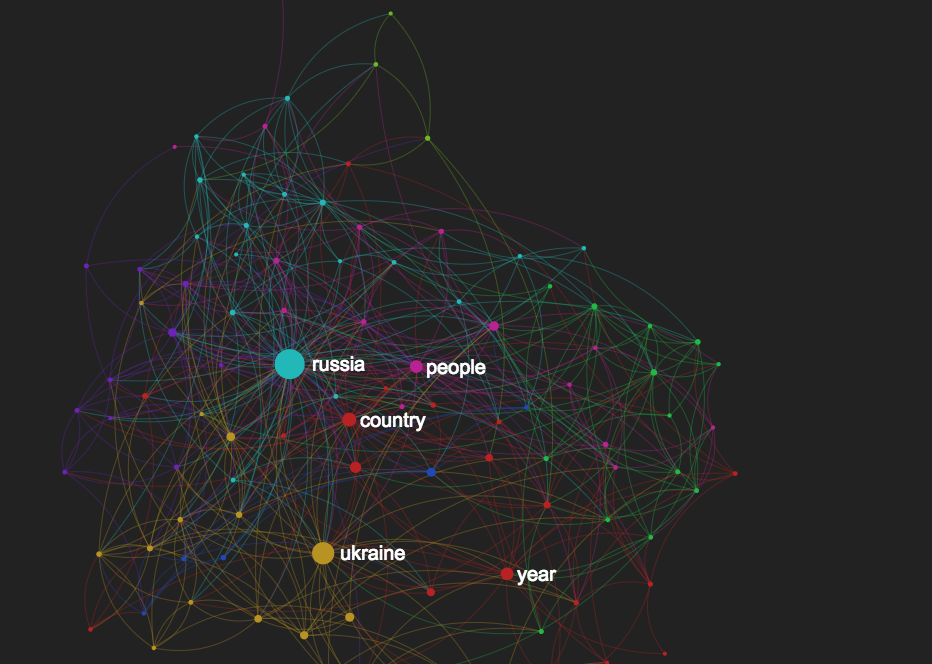
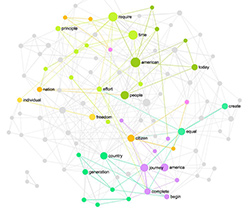
In this tutorial we present a method for topic modeling using text network analysis (TNA) and visualization. The approach we propose is based on identifying topical clusters in text based on co-occurrence of words. We will demonstrate how this approach can be used for topic modeling, how it compares to Latent Dirichlet Allocation (LDA), and how they can be used together to provide more relevant results.